




S3 Select is an AWS S3 feature that allows developers to run SQL queries on objects in S3 buckets. Here's an example.
SELECT s.zipcode, s.id FROM s3object s where s.name = 'Harshil'
Previously we wrote about the different ways you can write SQL with AWS. In this article, we will see how to configure and use S3 Select to make working with big datasets easier.
What is AWS S3 Select?
Amazon Simple Storage Solution (S3) is a limitless, durable, elastic, and cost-effective storage solution. However, applications using S3 often need to obtain a subset of a huge dataset, and processing the complete object each time to acquire a subset of the object is impossible. Because this influences the application's speed, Amazon S3 has created called S3 Select.
In other words, with S3, you no longer need to download, extract, process, and then get the output. S3 Select also supports various file types, including GZIP or BZIP2 compressed objects and server-side encrypted objects.

Advantages of S3 Select
S3 Select has a few benefits that make it a potential game-changer. First, since S3 Select functionality is available as an API, it does not require additional infrastructure or management. You can also easily integrate with other AWS tools and services like Lambda and EMR.
Furthermore, S3 Select can also increase the speed of most programs that frequently access data from S3 by up to 400% by minimizing the data that must be loaded and processed by your apps.
The amount of file types supported is another plus. CSV, GZIP, BZIP2, JSON, and Parquet files are all perfectly fine. It also supports GZIP or BZIP2 compressed objects and server-side encrypted objects.
Lastly, S3 queries are cost-effective. This comes naturally - the fewer results you return, the less you spend.
Limitation of S3 Select
Like any tool, though, S3 Select is not perfect. One limitation is that an SQL expression can have a maximum length of 256 KB. Additionally, the maximum length of a record in the input or result is 1 MB.
Furthermore, complex analytical queries and joins are not supported. And lastly, the select query can only run on one file at a time.
How much does it cost?
AWS provides a cost calculator, which we can use to estimate how much we'd need to spend on Select as compared to some other S3 offerings. Here is an estimated cost structure, which you can see in more detail here.
- S3 object storage — $0.02/GB
- S3 Select — $0.0004 per 1000 SELECT commands
- S3 Data Transfer— $0.01 per GB (U.S. East Region)
- Data Returned by S3 Select — $0.0007/GB
- Data Scanned by S3 Select — $0.002/GB
How to use S3 Select to perform a query
Ready to put what we've discussed into practice? Let's see how to use S3 Select to perform a query from the AWS console.
First, go to your S3 dashboard (search S3 in the AWS console). Here, you can choose to make a new bucket or use one that already exists. After you've created or selected your bucket, you'll need to upload the file you wish to query.
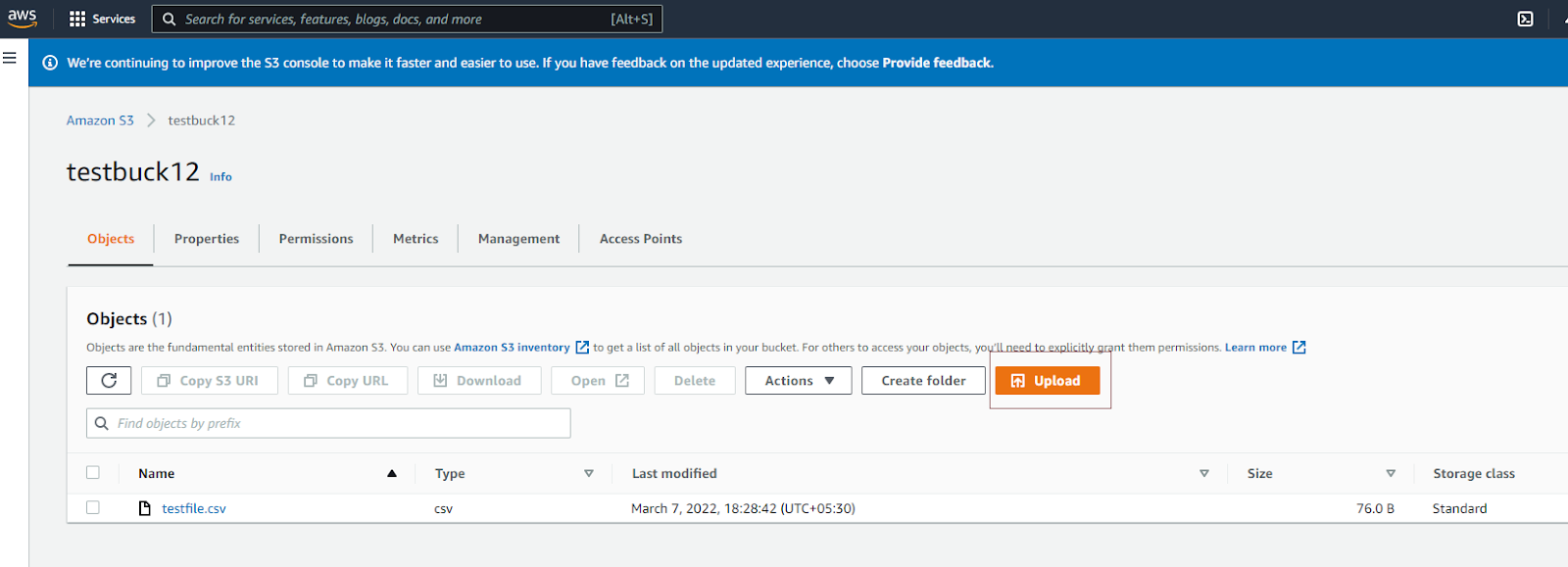
Once the upload is complete, you will see a success message.
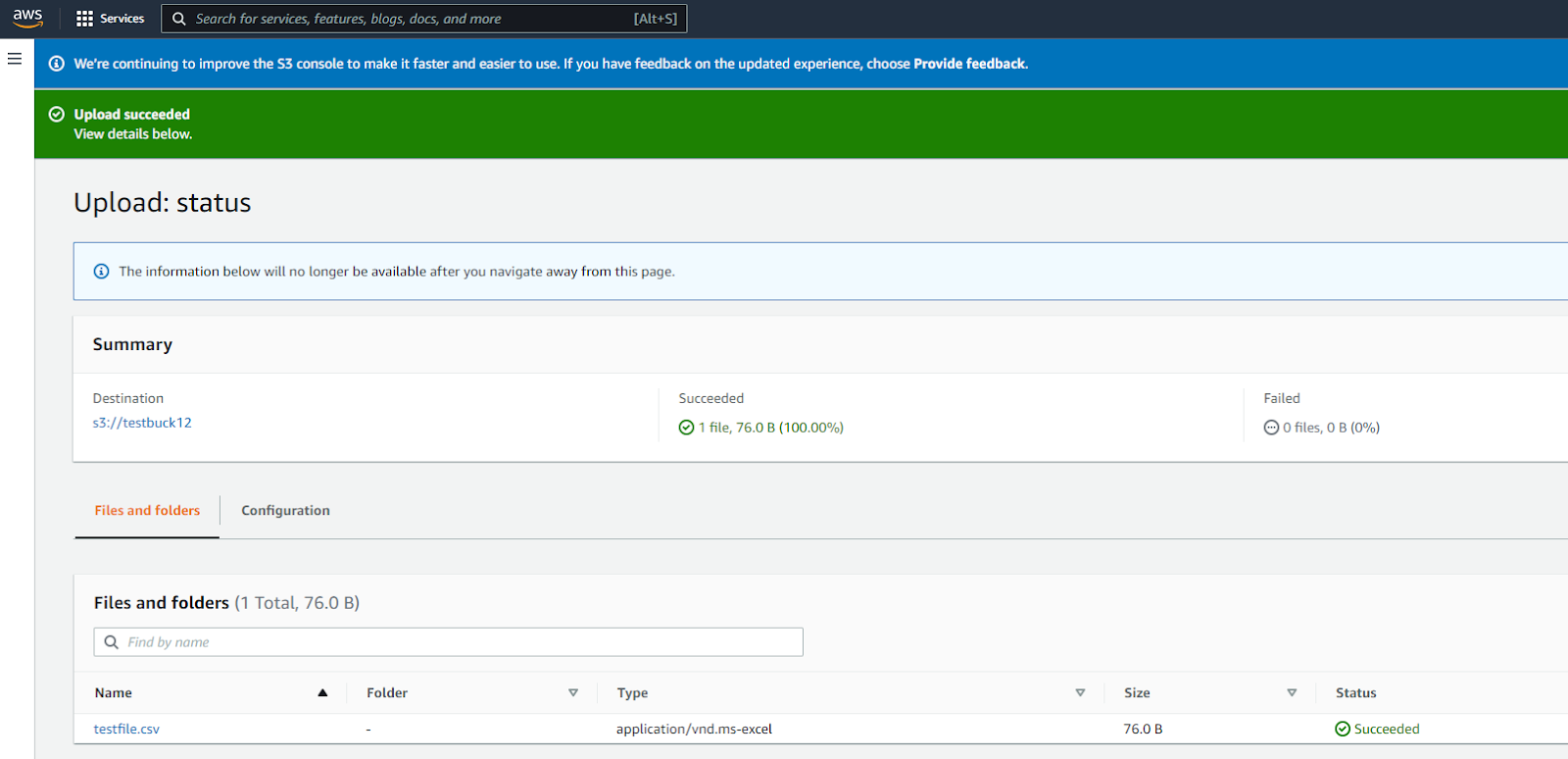
Now, go to Actions and choose Query with S3 Select after selecting the file you want to query.

Now, select the appropriate input and output setting depending on your file.
Note: If the first row of your file contains header data, select "Exclude the first line of CSV data."

Step 6: It's time to write queries now that you've defined all of your parameters. The picture below shows where to write a question and how the results will be shown.

The best part about S3 is that you can query your files using predefined templates. You can also save the results as CSV or JSON files.

When you're running queries, wouldn't it be easier to run and visualize all of your queries at one place? When working with a team, you might want a platform that allows you to manage analytics, display data, and collaborate. With Arctype, you can manage your databases and visualize your data. Workspaces can easily be shared, and its comprehensive access management makes inviting people and managing access rights a breeze. Now, let's run some queries on S3.
Let's run some queries.
For example, we will be using a CSV file with name, id, and zip code field. To start off, let's formulate a query to get the name and ID field from our CSV file:
SELECT s.name, s.id FROM s3object s
This returns the result below.

To take it a step further, we can also write a query to return the ID and Zipcode where Name is 'Harshil.'
SELECT s.zipcode, s.id FROM s3object s where s.name = 'Harshil'

I wonder how many people have the same zip code. We can answer that question with the following query:
SELECT * FROM s3object s WHERE CAST(s.zipcode as INTEGER) = 11311
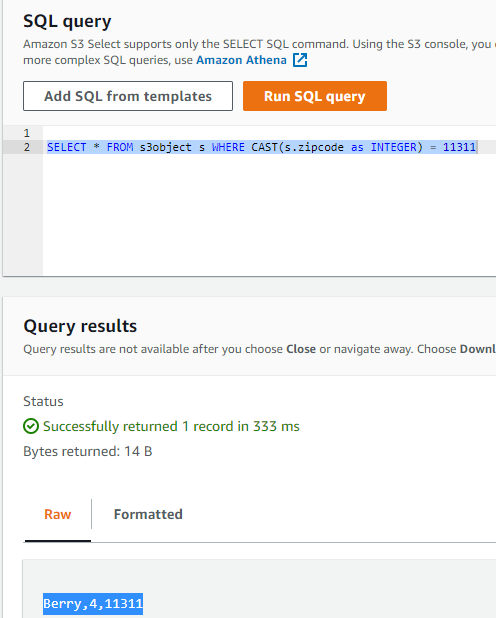
We can also use a simple count query to count the items in our file.
SELECT count(*) FROM s3object s

S3 Select with Python and AWS SDK
Let's say you have a big file in S3, you're building an application with Python, and you seek (no pun intended) to filter the file based on specific criteria. So you want to conduct some advanced querying and choose particular rows or columns. In that case, you can use S3 Select and Boto3.
The AWS SDK for Python (Boto3) provides a Python API for AWS infrastructure services. Using the SDK for Python, you can build applications on top of Amazon S3, Amazon EC2, Amazon DynamoDB, and more. You can simply import the necessary requirements using the code below.
import boto3
import pandas as pd
client = boto3.client('s3')
An example response is also shown:
response = client.select_object_content(
Bucket='string',
Key='string',
SSECustomerAlgorithm='string',
SSECustomerKey='string',
Expression='string',
ExpressionType='SQL',
RequestProgress={
'Enabled': True|False
},
InputSerialization={
'CSV': {
'FileHeaderInfo': 'USE'|'IGNORE'|'NONE',
'Comments': 'string',
'QuoteEscapeCharacter': 'string',
'RecordDelimiter': 'string',
'FieldDelimiter': 'string',
'QuoteCharacter': 'string',
'AllowQuotedRecordDelimiter': True|False
},
'CompressionType': 'NONE'|'GZIP'|'BZIP2',
'JSON': {
'Type': 'DOCUMENT'|'LINES'
},
'Parquet': {}
},
OutputSerialization={
'CSV': {
'QuoteFields': 'ALWAYS'|'ASNEEDED',
'QuoteEscapeCharacter': 'string',
'RecordDelimiter': 'string',
'FieldDelimiter': 'string',
'QuoteCharacter': 'string'
},
'JSON': {
'RecordDelimiter': 'string'
}
}
)
Conclusion
With S3 Select, you can use basic SQL queries to speed up S3 data querying efficiency. S3 Select may also be integrated with other AWS services to increase performance and lower costs. In simple terms, S3 Select will improve your data querying performance.