




MySQL introduced Window functions in their release of MySQL version 8.0. to target groups of rows without collapsing them. In this article, we will explore example implementations of the most versatile window functions MySQL has to offer.

Window Functions in MySQL
Window functions are an advanced feature offered by MySQL to improve the execution performance of queries. These functions act on a group of rows related to the targeted row called window frame. Unlike a GROUP BY clause, Window functions do not collapse the rows to a single row—preserving the details of each row instead. This new approach to querying data is invaluable in data analytics and business intelligence.
Window Functions vs. Aggregate Functions
Aggregate functions are used to return a single scalar value from a set of rows. Some prominent aggregate functions available in MySQL are SUM, MIN, MAX, AVG, and COUNT. We can use these functions combined with the GROUP BY clause to get an aggregated value.
In contrast, window functions return a corresponding value for each of the targeted rows. These targeted rows, or the set of rows on which the window function operates, is called a window frame. Window functions use the OVER clause to define the window frame. A window function can include an aggregate function as a part of its SQL statement by using the OVER clause instead of GROUP BY.
| AGGREGATE FUNCTIONS | WINDOW FUNCTIONS |
| Uses GROUP BY to define rows | Uses OVER to define rows (Window Frame) |
| Grouping based on the column values | Multiple grouping methods (row rank, percentile, column value) |
| Aggregates rows based on GROUP BY target | Returns a result for each row without collapsing rows |
| Calculate Aggregate amounts (Can only use aggregate functions) | Both aggregate functions and specialized window functions like LAG(), RANK(), etc. can be used |
| Uses a fixed group of values | Can be either a fixed or a sliding window frame |
What Are The Most Popular MySQL Window Functions?
The following are the specialized window functions MySQL offers:
| WINDOW FUNCTION | DESCRIPTION |
| CUME_DIST | Cumulative distribution of a value from a group of values |
| DENSE_RANK | The rank of the current row within the corresponding partition, without any gaps |
| RANK | The rank of the current row within the corresponding partition, with gaps |
| FIRST_VALUE | The corresponding value of the argument from the first row of the window frame |
| LAST_VALUE | The corresponding value of the argument from the last row of the window frame |
| LAG | Returns the value from the preceding (lagging) row for a given expression (argument) |
| LEAD | Returns the value from the following (leading) row for a given expression (argument) |
| NTH_VALUE | Returns the value of the expression (argument) from the N-th row of the window frame |
| NTILE | Divides a partition into groups (buckets) and returns the bucket number of the current row in the partition |
| ROW_NUMBER | The number of the current row within a partition. |
Please refer to the official MySQL documentation for in-depth information regarding each of the above functions.
Example Window Function Use Cases in MySQL
Now let’s see exactly how to utilize some of the Window functions mentioned above.
Creating Sample MySQL Database Tables
I will be using the latest MySQL server instance with Arctype as the SQL client. Following is the structure of our sample database:

We can use the following SQL script to create the table structure with Arctype client:
CREATE TABLE departments (
dep_id INT (10) AUTO_INCREMENT PRIMARY KEY,
dep_name VARCHAR (30) NOT NULL,
dep_desc VARCHAR (150) NULL
);
CREATE TABLE employees (
emp_id INT (10) AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR (20) NOT NULL,
last_name VARCHAR (25) NOT NULL,
email VARCHAR (100) NOT NULL,
phone VARCHAR (20) DEFAULT NULL,
salary DECIMAL (8, 2) NOT NULL,
dep_id INT (10) NOT NULL,
FOREIGN KEY (dep_id) REFERENCES
departments (dep_id)
ON DELETE CASCADE
ON UPDATE CASCADE
);
CREATE TABLE evaluations (
eval_id INT (10) AUTO_INCREMENT PRIMARY KEY,
emp_id INT (10) NOT NULL,
eval_date DATETIME NOT NULL,
eval_name VARCHAR (30) NOT NULL,
notes TEXT DEFAULT NULL,
marks DECIMAL (4,2) NOT NULL,
FOREIGN KEY (emp_id) REFERENCES employees (emp_id)
);
CREATE TABLE overtime (
otime_id INT (10) AUTO_INCREMENT PRIMARY KEY,
emp_id INT (10) NOT NULL,
otime_date DATETIME NOT NULL,
no_of_hours DECIMAL (4,2) NOT NULL,
FOREIGN KEY (emp_id) REFERENCES employees (emp_id)
);
After creating the tables, we can insert some sample data into each table using proper relationships. Now, let’s get back into Window functions.
Sort and Paginate Results with ROW_NUMBER()
In our sample database, the employee table is arranged according to the emp_id. However, if we need to get a separate sequential number assigned to each row, then we can use the ROW_NUMBER() window function.
In the following example, we are using the ROW_NUMBER() function while ordering each row by salary amount.
We will get the following result if we query just using the GROUP BY clause.
SELECT * FROM employees ORDER BY salary DESC;

SELECT
ROW_NUMBER() OVER( ORDER BY salary DESC) `row_num`,
first_name,
last_name,
salary
FROM
employees;
RESULT:
WITH page_result AS (
SELECT
ROW_NUMBER() OVER(
ORDER BY salary DESC
) `row_num`,
first_name,
last_name,
salary
FROM
employees
)
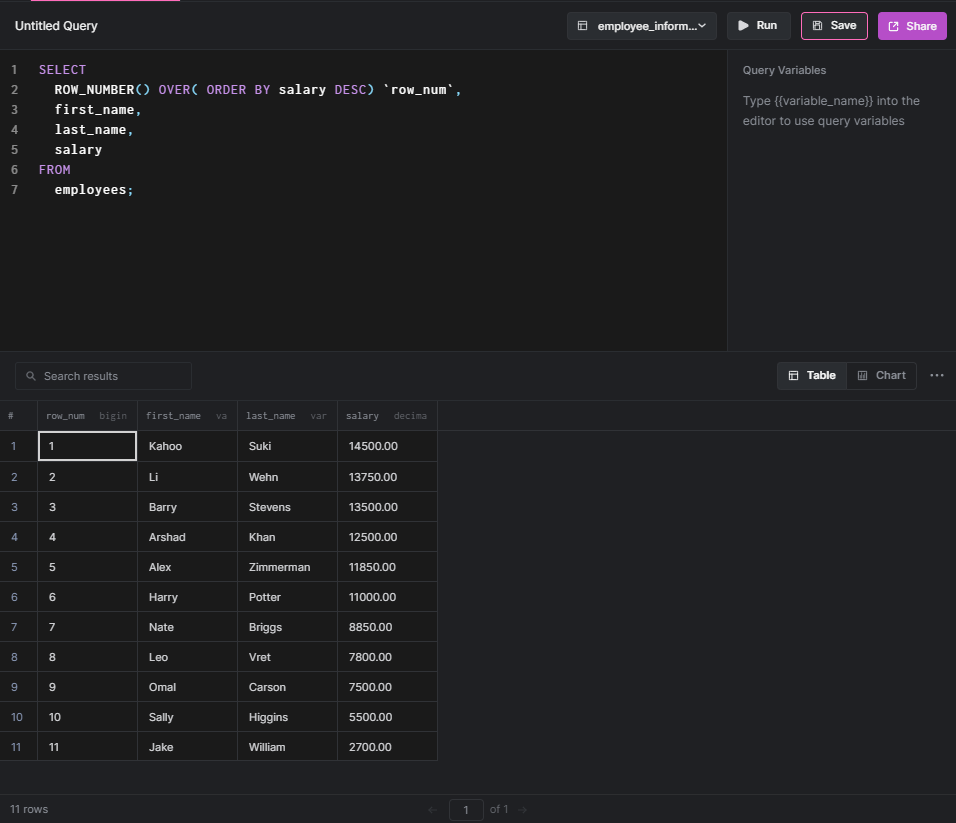
SELECT * FROM page_result WHERE `row_num` BETWEEN 6 AND 10
RESULT:
Using PARTITION BY in a MySQL Window Function
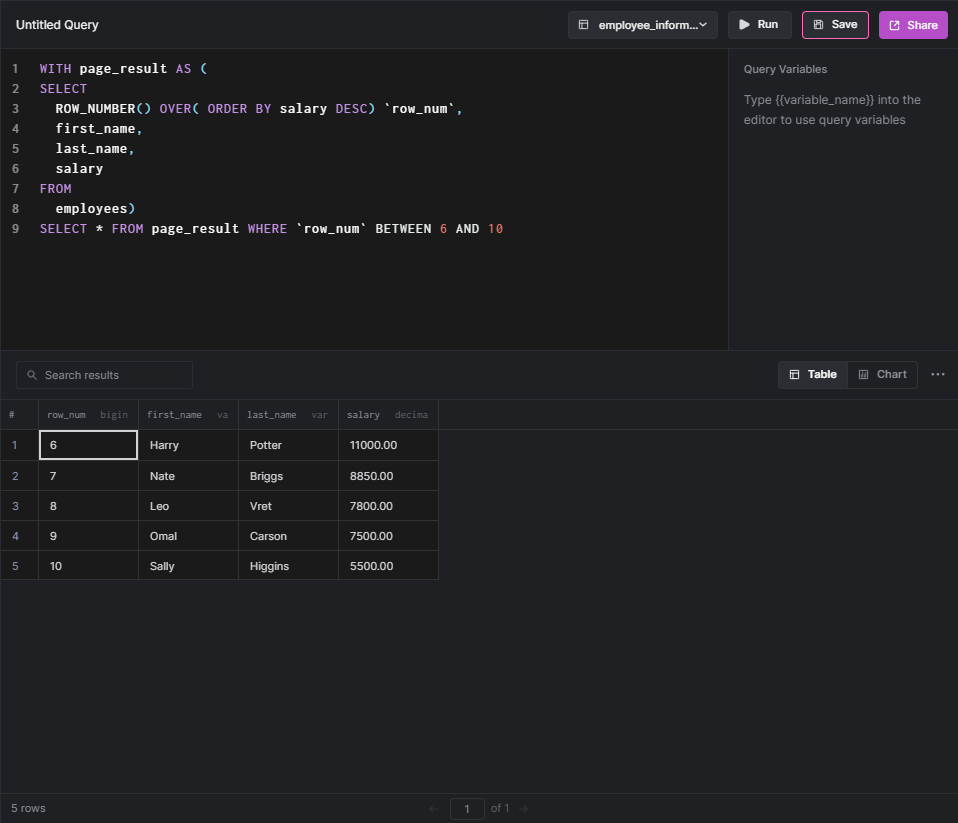
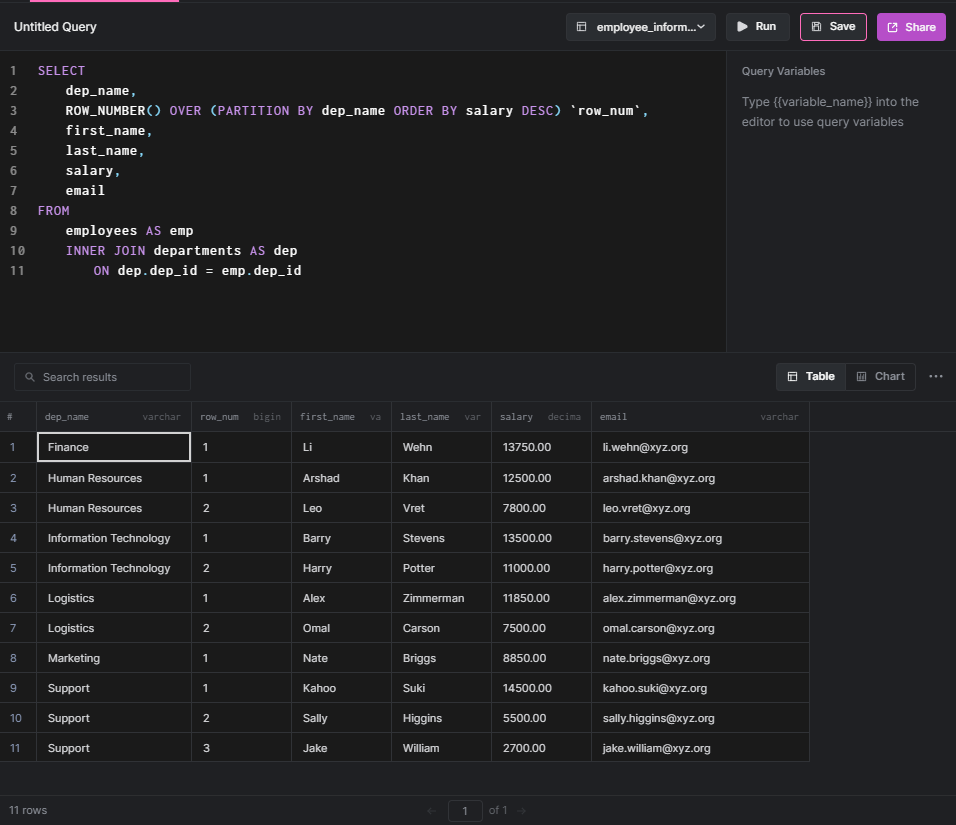
Using the PARTITION BY clause enables us to partition employees based on the department. The following query can be used to get the salary scale of employees partitioned by each department.
SELECT
dep_name,
ROW_NUMBER() OVER (
PARTITION BY dep_name
ORDER BY salary DESC
) `row_num`,
first_name,
last_name,
salary,
email
FROM
employees AS emp
INNER JOIN departments AS dep
ON dep.dep_id = emp.dep_id
RESULT:
SELECT
ROW_NUMBER() OVER (
ORDER BY dep_name DESC
) `row_num`,
dep_name,
first_name,
last_name,
salary,
email
FROM
(
SELECT
dep_name,
ROW_NUMBER() OVER (
PARTITION BY dep_name
ORDER BY salary DESC
) `row_num`,
first_name,
last_name,
salary,
email
FROM
employees AS emp
INNER JOIN departments AS dep
ON dep.dep_id = emp.dep_id
) AS highest_paid
WHERE
`row_num` = 1
RESULT:

Comparing Row Values Using LAG()
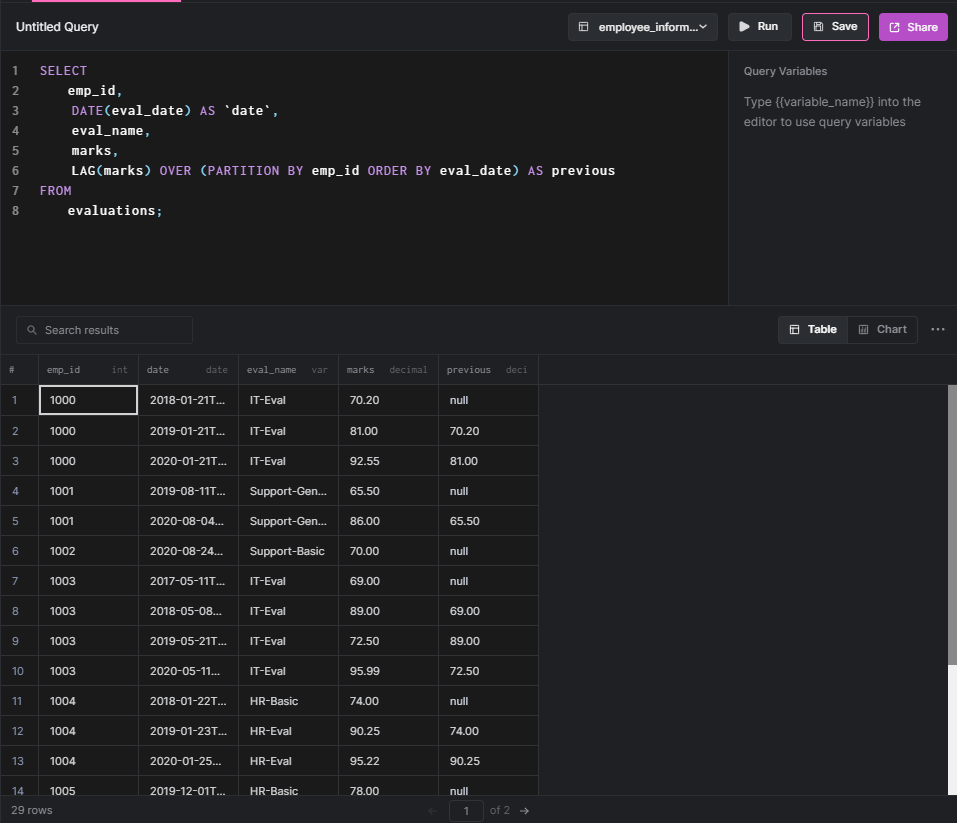
The LAG function enables users to access preceding rows using a specified offset. This kind of function is useful when we need to compare the values of the preceding rows with the current row. In our data set, we have a table named evaluations which include yearly employee evaluations. Using LAG, we can identify the performance of each employee and determine if they have improved or not.
First, let us write a query against the “evaluations” table to identify the basic output of the LAG function. In that query, we will partition employees by emp_id (employee id) and order that partition by the eval_date (evaluation date).
SELECT
emp_id,
DATE(eval_date) AS `date`,
eval_name,
marks,
LAG(marks) OVER (
PARTITION BY emp_id ORDER BY eval_date
) AS previous
FROM
evaluations;
RESULT:
WITH emp_evaluations AS (
SELECT
emp_id,
YEAR(eval_date) AS `year`,
eval_name,
marks,
LAG(marks,1,0) OVER (
PARTITION BY emp_id
ORDER BY eval_date
) AS previous
FROM
evaluations
)
SELECT
emp_id,
`year`,
eval_name,
marks,
previous,
IF (previous = 0, '0%',
CONCAT(ROUND((marks - previous)*100/previous, 2), '%')
) AS difference
FROM
emp_evaluations;
In the above query, we have defined a common table expression (CTE) to obtain the results of the initial LAG query called emp_evaluations. There are a couple of differences from the original query.
One is that here, we are extracting only the year value from the eval_date DATETIME field, and the other is that we have defined an offset and a default value (1 as the offset and 0 as the default value) in the LAG function. This default value will be populated when there are no previous rows, such as the beginning of each partition.
Then we query the emp_evaluations result set to calculate the difference between the “marks” and the “previous” column for each row.
Here we have defined an IF condition to identify empty previous values (previous = 0) and show them as no difference (0%) or otherwise calculate the difference. Without this IF condition, the first row of each partition will be shown as a null value. This query will provide the following formatted output as a result.

Assigning Ranks to Rows with DENSE_RANK()
The DENSE_RANK function can be used to assign ranks to rows in partitions without any gaps. If the targeted column has the same value in multiple rows, DENSE_RANK will assign the same rank for each of those rows.
In the previous section, we identified the year-over-year performance of employees. Now let’s assume that we are offering a bonus to the most improved employee in each department. In that case, we can use DENSE_RANK to assign a rank to the performance difference of employees.
First, let us modify the query in the LAG function section to create a view from the resulting data set. As we simply need to query (SELECT) the data here, a MySQL view would be an ideal solution. We have modified the SELECT statement in emp_evaluations to include the relevant department, first and last names by joining the evaluations, employees, and departments tables.
CREATE VIEW emp_eval_view AS
WITH emp_evaluations AS (
SELECT
eval.emp_id AS `empid`,
YEAR(eval.eval_date) AS `eval_year`,
eval.eval_name AS `evaluation`,
eval.marks AS `mark`,
LAG(eval.marks,1,0) OVER (
PARTITION BY eval.emp_id
ORDER BY eval.eval_date
) AS `previous`,
dep.dep_name AS `department`,
emp.first_name AS `first_name`,
emp.last_name AS `last_name`
FROM
evaluations AS eval
INNER JOIN employees AS emp ON emp.emp_id = eval.emp_id
INNER JOIN departments AS dep ON dep.dep_id = emp.dep_id
)
SELECT
empid,
first_name,
last_name,
department,
`eval_year`,
evaluation,
mark,
previous,
IF (previous = 0, '0%',
CONCAT(ROUND((mark - previous)*100/previous, 2), '%')
) AS difference
FROM
emp_evaluations;
RESULT:
eval_year = 2020).
SELECT
empid,
first_name,
last_name,
department,
`eval_year`,
evaluation,
difference AS 'improvement',
DENSE_RANK() OVER (
PARTITION BY Department
ORDER BY Difference DESC
) AS performance_rank
FROM
emp_eval_view
WHERE
`eval_year` = 2020
RESULT:

SELECT *
FROM (
SELECT
empid,
first_name,
last_name,
department,
`eval_year`,
evaluation,
difference AS 'improvement',
DENSE_RANK() OVER (
PARTITION BY Department
ORDER BY Difference DESC
) AS performance_rank
FROM
emp_eval_view
WHERE
`eval_year` = 2020
) AS yearly_performance_data
WHERE
performance_rank = 1
RESULT:

Use FIRST_VALUE and LAST_VALUE() to Get First and Last Values from a Partition
The FIRST_VALUE function enables users to get the first value from an ordered partition while LAST_VALUE gets the opposite, the last value of a result set. These functions can be used for our data set to identify the employees who did the least and most overtime in each department.
FIRST_VALUE()
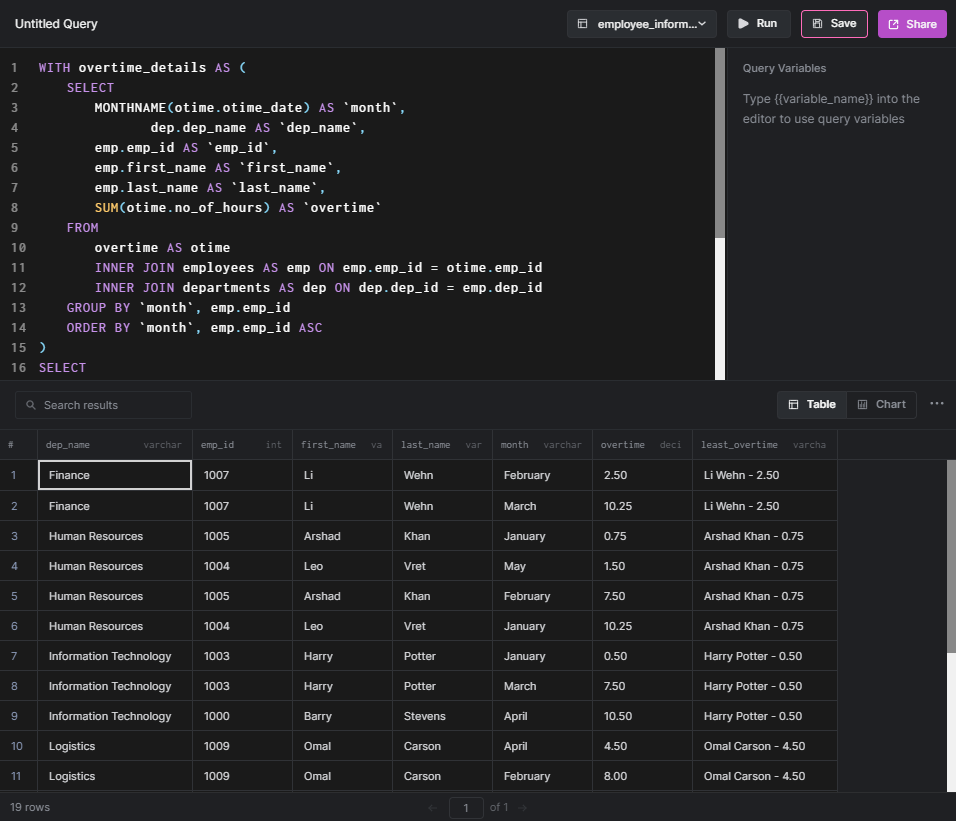
We can use the FIRST_VALUE function to get the employees who did the least overtime in each respective department.
In the following SQL statement, we have defined a common table expression to calculate overtime done by each employee for each month using the SUM aggregate function. Then using the FIRST_VALUE window function, we are getting the concatenated details (first and last names with the overtime value) of the employee who did the least overtime in a specific department. This partitioning is done via the PARTITION BY statement.
WITH overtime_details AS (
SELECT
MONTHNAME(otime.otime_date) AS `month`,
dep.dep_name AS `dep_name`,
emp.emp_id AS `emp_id`,
emp.first_name AS `first_name`,
emp.last_name AS `last_name`,
SUM(otime.no_of_hours) AS `overtime`
FROM
overtime AS otime
INNER JOIN employees AS emp ON emp.emp_id = otime.emp_id
INNER JOIN departments AS dep ON dep.dep_id = emp.dep_id
GROUP BY `month`, emp.emp_id
ORDER BY `month`, emp.emp_id ASC
)
SELECT
dep_name,
emp_id,
first_name,
last_name,
`month`,
overtime,
FIRST_VALUE (CONCAT(first_name,' ',last_name,' - ',overtime)) OVER (
PARTITION BY dep_name
ORDER BY overtime
) least_overtime
FROM
overtime_details;
This will provide a result set similar to the following, indicating the employee who did the least over time.
LAST_VALUE()
We can use the LAST_VALUE window function to get the employee who did the most amount of overtime in each department. The syntax and the logic are identical to the FIRST_VALUE SQL statement yet with the addition of a “frame clause” to define a subset of the current partition where the LAST_VALUE function needs to be applied.
We are using the:
RANGE BETWEEN
UNBOUNDED PRECEDING AND
UNBOUNDED FOLLOWING
as the frame clause. This essentially informs the database engine that the frame starts at the first row and ends at the last row of the result set. (In our query, this applies to each partition)
WITH overtime_details AS (
SELECT
MONTHNAME(otime.otime_date) AS `month`,
dep.dep_name AS `dep_name`,
emp.emp_id AS `emp_id`,
emp.first_name AS `first_name`,
emp.last_name AS `last_name`,
SUM(otime.no_of_hours) AS `overtime`
FROM
overtime AS otime
INNER JOIN employees AS emp ON emp.emp_id = otime.emp_id
INNER JOIN departments AS dep ON dep.dep_id = emp.dep_id
GROUP BY `month`, emp.emp_id
ORDER BY `month`, emp.emp_id ASC
)
SELECT
dep_name,
emp_id,
first_name,
last_name,
`month`,
overtime,
LAST_VALUE (CONCAT(first_name,' ',last_name,' - ',overtime)) OVER (
PARTITION BY dep_name
ORDER BY overtime
RANGE BETWEEN
UNBOUNDED PRECEDING AND
UNBOUNDED FOLLOWING
) most_overtime
FROM
overtime_details;
This would provide us with the details of the employees who did the most overtime in each department.

Conclusion
Window functions in MySQL are a welcome addition to an already excellent database. In this article, we mainly covered how to use window functions with some practical examples. The next step is to dig even further into MySQL window functions and mix them with all the other available MySQL functionality to meet any business requirement.